Automatic speaker recognition technology and spoofing attacks: an overview by Bhusan Chettri
How computers can automatically recognize a person using voice? Can AI be used to fool computers? What do you have to do to protect automatic speaker verification systems against fraudulent access? Curious to know? Ok, then this article is for you.
London, England Jul 1, 2022 (Issuewire.com) – Machine learning for Voice technology. An overview of automatic speaker authentication using voice & spoofing attacks by Bhusan Chettri.
Dr. Bhusan Chettri earned his Ph.D. in AI and Speech Technology from the Queen Mary University of London. His research focused on the analysis and design of voice spoofing detection using machine learning and AI. In this article Bhusan Chettri gives an insight on machine learning for voice where he introduces how computers can be used to automatically authenticate a person using voice; he also talks about how such technology can be manipulated using AI; Finally, he summarizes the community-driven effort (ASVspoof) towards protecting voice biometrics from being manipulated where a bi-annual open spoofing detection challenge is organized by the speech community releasing big data for anti-spoofing research free of cost to the community towards promoting the voice anti-spoofing research.
Automatic Speaker Recognition is the task of recognizing humans through their voices by using a computer. Automatic Speaker Recognition comprises two tasks: Speaker identification and Speaker verification. Speaker identification involves finding the correct person from a given pool of known speakers or voices. A speaker identification usually comprises a set of N speakers who are already registered in the system and these N speakers can only have access to the system. Speaker verification on the other hand involves verifying whether a person is who he/she claims to be using their voice sample. These systems are further classified into two categories depending upon the level of user cooperation: (1) Text-dependent and (2) Text independent. In text-dependent applications, the system has prior knowledge of the spoken text and therefore expects the same utterance during test time (or deployment phase). For example, a pass-phrase such as “My voice is my password” will be used both during speaker enrollment (registration) and during deployment (when the system is running). On the contrary, in text-independent systems, there is no prior knowledge about the lexical contents, and therefore these systems are much more complex than text-dependent ones.
Although today’s speaker verification systems driven by deep learning and big data shows superior performance in verifying a speaker, they are not secure. They are prone to spoofing attacks. In this article, Dr. Bhusan Chettri gives an overview of the technology used for spoofing a voice authentication system that uses automatic speaker verification (ASV) technology.
Spoofing attacks in ASV: an overview by Dr. Bhusan Chettri
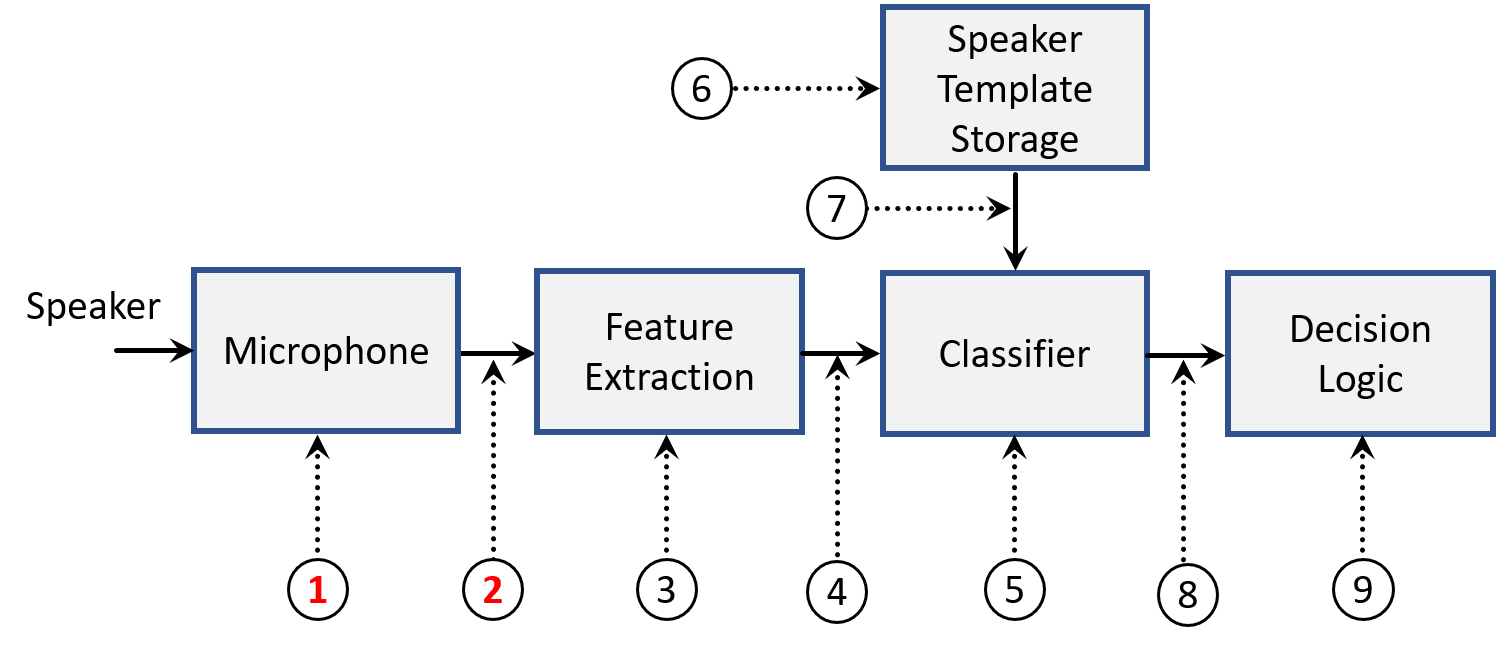
A spoofing attack (or presentation attack ) involves illegitimate access to the personal data of a targeted user. These attacks are performed on a biometric system to provoke an increase in its false acceptance rate. The security threats imposed by such attacks are now well acknowledged within the speech community. As identified in the ISO/IEC 30107-1 standard, a biometric system could be potentially attacked from nine different points. Fig. 1 provides a summary of this. The first two attack points are of specific interest as they are particularly vulnerable in terms of enabling an adversary to inject spoofed biometric data. These two points are commonly referred to as physical access (PA) and logical access (LA) attacks. As illustrated in the figure, PA attacks involve presentation attacks at the sensor (microphone in case of ASV) level and LA attacks involve modifying biometric samples to bypass the sensor. Text-to-speech and voice conversion techniques are used to produce artificial speech to bypass an ASV system. These two methods are examples of LA attacks. On the other hand, mimicry and playing back speech recordings (replay) are examples of PA attacks.
Figure 1 (see the attached picture): Possible locations [ISO/IEC, 2016] to attack an ASV system. 1: microphone point, 2: transmission point, 3: override feature extractor, 4: modify features, 5: override classifier, 6: modify speaker database, 7: modify biometric reference, 8: modify the score, and 9: override the decision.
Therefore, it is very important to secure these systems from being manipulated. For this, spoofing countermeasure solutions are often integrated into the verification pipeline. And, voice spoofing countermeasures are currently an active research topic within the speech research community. Next, Dr. Bhusan Chettri will be talking more about how AI and big data can be used to design anti-spoofing solutions in order to protect voice authentication systems from spoofing attacks.
An overview of the ASVspoof challenge: ASVspoof is an ASV community-driven effort promoting research in developing anti-spoofing algorithms for secure voice biometrics. A number of independent research studies had confirmed the vulnerability of voice biometrics to spoofing attacks, before the ASVspoof series began in 2015. However, these studies were mostly performed on small in-house datasets comprising limited speakers and spoofing attack conditions. Therefore, research results were hard to reproduce, and understanding the true generalisability of the reported anti-spoofing solutions in unseen attack conditions was difficult. The main motivation of the ASVspoof series was to overcome these issues by organising open spoofing challenge evaluations, promoting awareness of the problem, making publicly available spoofing corpora comprising sufficiently varying attack conditions with standard evaluation protocols, and further ensuring transparent research leading to reproducible results.
One key observation that is worth noting from the three ASVspoof challenges is the paradigm shift in the use of modelling approaches for spoofing detection. Gaussian mixture models (GMMs), which is a generative model, were popular during the first ASVspoof challenge in 2015 as evident from the winning system of this challenge which is a GMM-based system. However, the 2017 and 2019 spoofing challenges were mostly dominated by data-driven discriminatively trained deep models. The main task, however, in all the three editions of the ASVspoof challenge was to build a standalone countermeasure model (anti-spoofing algorithm) that determines if a given speech recording is bonafide or a fake recording (spoofed). As for the performance evaluation, the equal error rate (EER) was used as a primary metric in the 2015 and 2017 editions. As for the 2019 edition, a recently introduced tandem detection cost function (t-DCF) metric was used as a primary metric and EER as the secondary metric.
Related link:
[1] M. Sahidullah et. al. Introduction to Voice Presentation Attack Detection and Recent Advances, 2019.
[2]. Bhusan Chettri. Voice biometric system security: Design and analysis of countermeasures for replay attacks. Ph.D. thesis, Queen Mary University of London.


Source :https://theses.eurasip.org/theses/866/voice-biometric-system-security-design-and/
This article was originally published by IssueWire. Read the original article here.